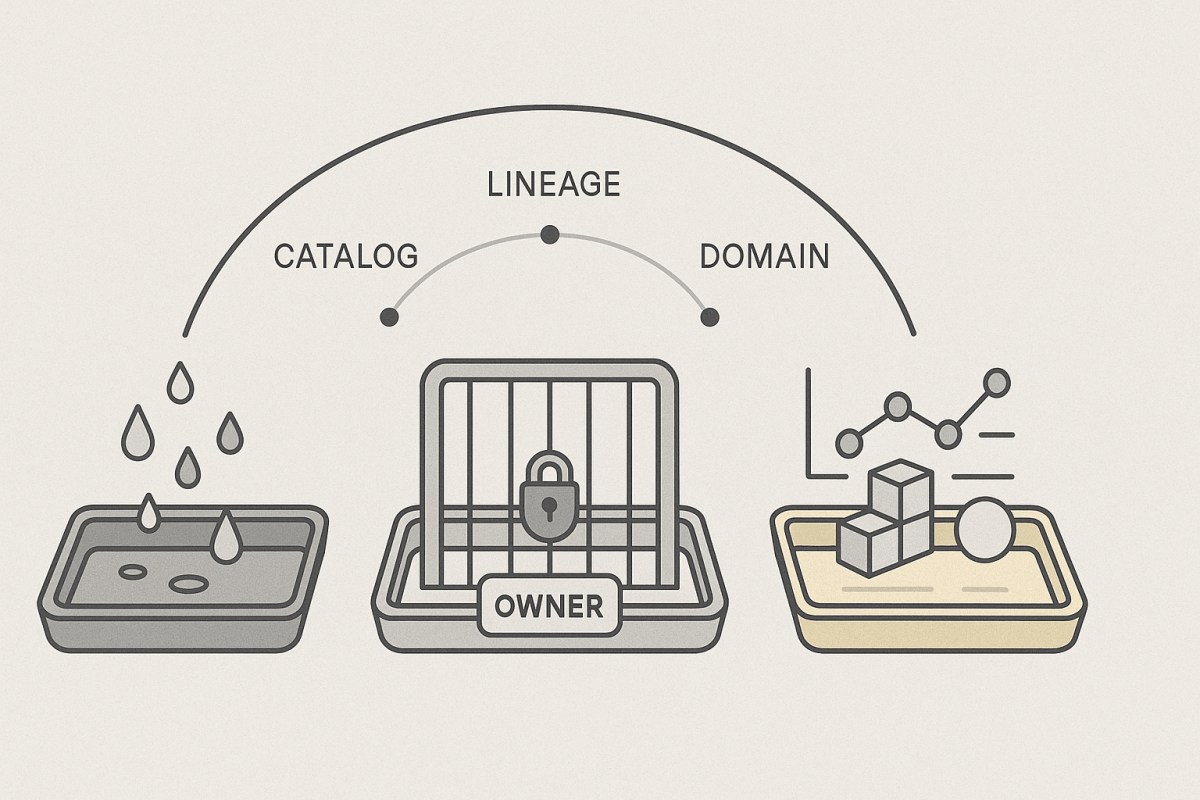
Schema changes have always been risky because a schema isn’t just columns—it’s the interface between data producers and data consumers. Historically, that interface was rigid, which made any change expensive. Modern lakehouse design solves the problem structurally: a Medallion architecture separates where variation is tolerated (Bronze) from where commitment is made (Silver) and relied upon (Gold). In Microsoft Fabric, those roles map cleanly to Lakehouse, Warehouse, and Power BI’s semantic layer, with governance and domain‑oriented (data‑product) design tying it all together. By the end, you’ll see why schema evolution is both inevitable and manageable—and how Fabric builds that manageability into the platform.
Continue reading “Making Schema Change Boring: A Short History—and How Microsoft Fabric’s Medallion Lakehouse Bakes It In”Tag: Data Modeling
Why Star Schemas Make Analysts Faster (and Happier)

If you live in spreadsheets or SQL all day, the “one big table” (OBT) feels like home. Everything you need is right there: one row per thing, a column for every attribute, and no joins to worry about. It’s a great way to explore data fast—until it isn’t. This post explains, in plain language, why the star schema pays you back every day you analyze data, and how it keeps the speed you love without the headaches you’ve learned to live with.
Continue reading “Why Star Schemas Make Analysts Faster (and Happier)”Slowly Changing Dimensions (SCDs): A Practical Guide for Your Star Schema
Star schemas shine when your facts (events) are analyzed through dimensions (who/what/where/when). But in real life, dimension attributes change—customers move, products rebrand, sales territories realign. Slowly changing dimensions (SCDs) are the modeling patterns that preserve analytic correctness as those attributes evolve.
Continue reading “Slowly Changing Dimensions (SCDs): A Practical Guide for Your Star Schema”Implementing Stars and Galaxies in Power BI

Power BI rewards clean dimensional models—but it also punishes sloppy ones. This post walks through how to implement star and galaxy schemas in Power BI semantic models, why ambiguous (multiple) filter paths cause headaches, why implicit measures don’t scale beyond the simplest star, and how tightly defined data products keep your BI ecosystem fast, correct, and governable. Because this is such an important topic, I’ve included links to references with each point.
Continue reading “Implementing Stars and Galaxies in Power BI”A Practical Introduction to Star Schema Data Architecture
Dimensional modeling remains the most effective way to make analytics fast, understandable, and resilient. The star schema sits at the center of that approach: a simple, denormalized structure where fact tables record measurable events and dimension tables provide descriptive context. In this post, we’ll ground the core ideas, clarify the often‑confused concept of snowflaking (and when it’s worth it), and show how to scale from a single star to a galaxy schema (a.k.a. fact constellation) without losing your footing.
Continue reading “A Practical Introduction to Star Schema Data Architecture”Foundational + Derived Data Products in a Data Mesh

A data mesh is a sociotechnical approach to analytical data that decentralizes responsibility to business domains while standardizing the way data is produced and consumed. It’s grounded in four principles: domain ownership, data as a product, a self‑serve data platform, and federated governance. In practice, it asks each domain team to publish data as a product—discoverable, trustworthy, and operable—while a common platform automates cross‑cutting rules (access, lineage, quality, security).
Zhamak Dehghani frames a data product as an architectural quantum: the smallest independently deployable unit that bundles data, code, metadata, and policy, with a versioned contract and a clear interface (APIs or governed views). Treating both foundational and derived products as quanta is the key to decoupled evolution without breaking interoperability.
Continue reading “Foundational + Derived Data Products in a Data Mesh”